DTP1部のTです。
今回のブログではPDFからしおりのテキストを抽出、そのテキストを使用して別のPDFにしおりを作成する方法をご紹介していきたいとおもいます。
そもそも、そんな作業することがあるのかと疑問におもう方もいるかと思いますので、まずはどういった時に使用するのかといった所から。
昨今では以前よりも2次利用を目的としてPDFを作成する書籍が増えてきていますが、その中でも年度版で毎年再版を行うものは修正箇所が少なく、目次に修正がない場合などがあります。
そういった時にこれからご紹介する方法を使用することで手間のかかるしおり作成の作業時間を大幅に短縮することができます。
それではまず抽出を行うPDFをAcrobatで開き、デバッカーのコンソールに下記のスクリプトを貼り付けます。
function DumpBookmark(bkm, nLevel)
{
var s = "";
for (var i = 0; i < nLevel; i++) s += "\t";
bkm.execute();
console.println(s + bkm.name + "\t" + this.pageNum);
if (bkm.children != null)
for (var i =0; i < bkm.children.length; i++)
DumpBookmark(bkm.children[i], nLevel + 1);
}
console.clear(); console.show();
console.println("Dumping all bookmarks in the document.");
DumpBookmark(this.bookmarkRoot, 0);
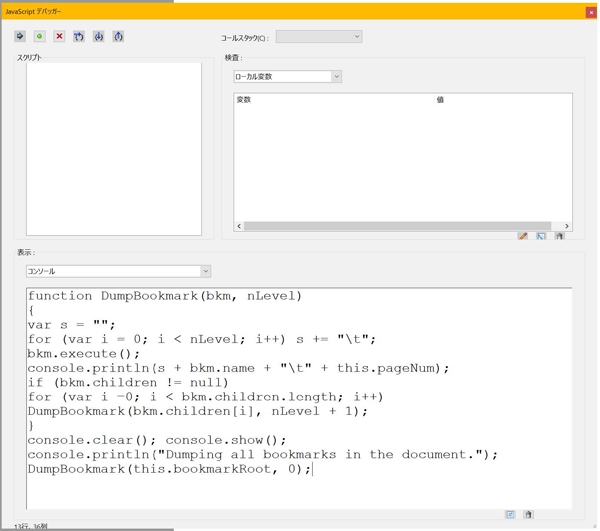
貼り付けたらテキストを全選択し、Enterを押します。
すると抽出が始まり、スクリプトを貼り付けたところに項目とページ番号が抽出されます。
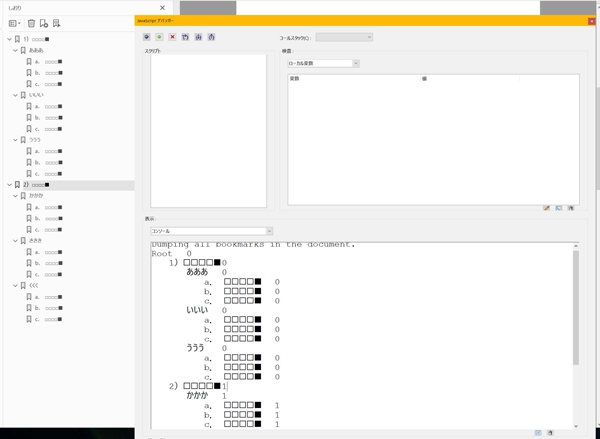
抽出テキストをテキストエディタに貼り付け、先頭にある
Dumping all bookmarks in the document.
Root 0
最終行の
undefined
は不要なので削除します。
これで抽出作業は完了です。
ここからこのテキストをもう一度しおりとして読み込ませるために、タグをつけていきます。
基本的な形は以下のようになります。
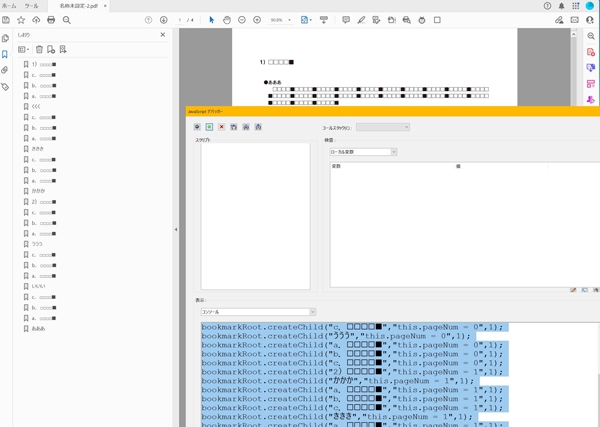
bookmarkRoot.createChild(" ●●● ","this.pageNum = 0",1);
最後にある数字(上記の見本では1になっている箇所)は、しおりを流し込む時の順番になります。
これを指定しておかないと流し込んだときに順番がおかしくなってしまうので注意してください。
タグをつけ終えたら新たにしおりを読み込ませるPDFを開きます。
そして抽出するときと同様にデバッカーのコンソールにタグをつけたテキストを貼り付け、全選択しEnter を押します。
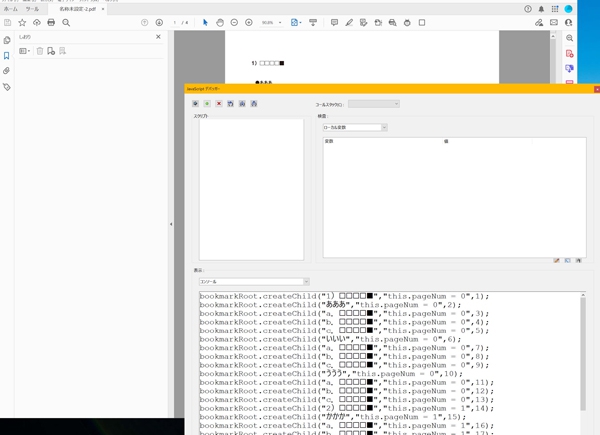
そうするとテキストが読み込まれ、新たにしおりが作成されます。
成功例
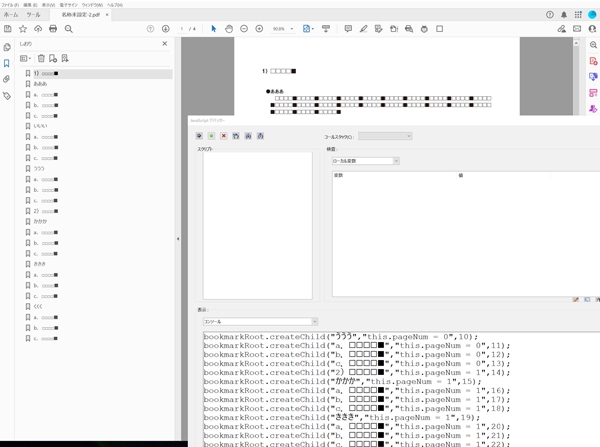
失敗例(順番の数字が全て1の場合)
これで一先ずしおりは作成されました。
ただこれだけだと元々あった階層がなくなってしまったり、前付けのノンブルに時計数字を使用しているとしおりをクリックした
ときに正しいページに飛ばないなどの問題が発生してしまいます。
そういった問題を解決するためにデータベースソフト等を利用してここから手を加えていくのですが、
話しが長くなってしまうのでそれはまた次回にお話ししたいとおもいます。
2つの異なる絵柄をスキャニングして間違い探しをしてみた
IT・情報処理室のMです。
以前よりプログラミング言語のPythonによる画像解析に興味がありましたので、今回は若干絵柄が異なる2つの紙媒体をスキャニングして画像解析による比較を検証してみたいと思います(ちなみに左右の絵柄で間違いが5箇所あります)。

画像を比較する際に同一データから作成された画像は座標値が一致していることが多く、Acrobatの『ファイルの比較』などのツールを使用して誤差の検知ができるのですが、紙媒体をスキャニングして比較する場合には、スキャニングする際に歪み生じてしまったり、座標値がズレてしまうため画像が完全に重ならないので、ツールを使用しても誤差の検知が難しいのが現状です。
そこで今回はPythonの画像解析ライブラリを用いて『1.スキャニングした2つの画像の座標値を補正』『2.座標値を補正した画像を使用して誤差の検知』の2工程にて画像の比較を実施しました。
1.スキャニングした2つの画像の座標値を補正

2.座標値を補正した画像を使用して誤差の検知(類似性が約89%)
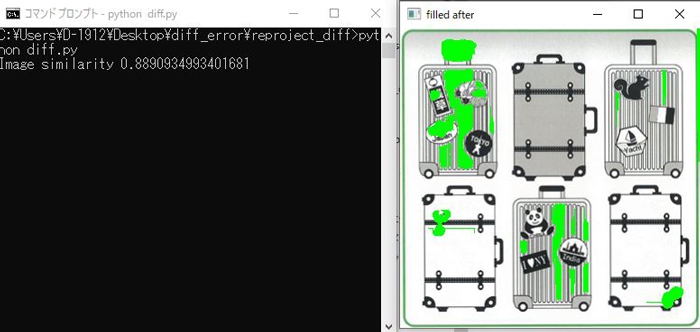
比較結果としては誤差がいない箇所も検知してしまったのですが、画像解析時の閾値を調整することにより誤検知を減らすことができると思われます。
最後に、Pythonには画像解析のライブラリが多数存在し、比較的簡単にプログラムを記述することができるので興味がある方はチャレンジしてみてはいかがでしょうか。
生産部のHです。
前回に続いて「データベースの活用」についてです
一般的にデータの入稿形態となると本文はワード,図表はエクセルが多いのではないか…? と思いますが,中にはエクセルデータ一本で数百ページの「本文を組む」そういった作業もあります.
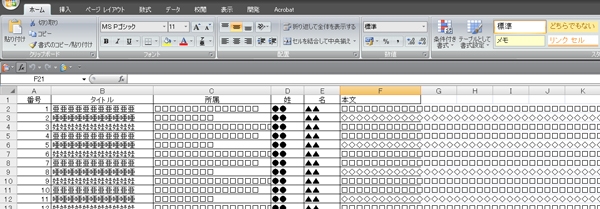
その場合,入稿するのはデータのみで「紙の原稿が無い」校正には原稿となるものが必要なわけですが,下記のようなエクセルデータをそのまま印刷したら,プリントされるものは大変なことになってしまいます.
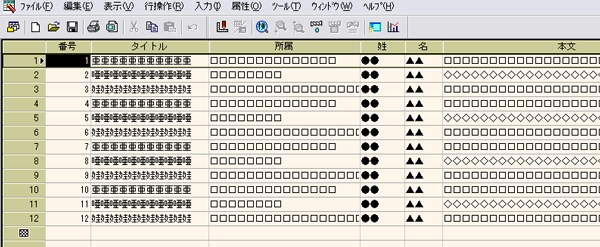
そこで,今回もデータベースソフトの「桐」を使用します(下記図参照).インポートはエクセルデータを桐の画面にドロップするだけです.
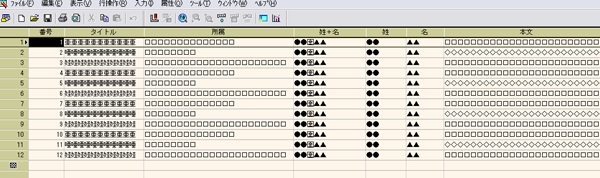
姓名の「姓」と「名」が別々の列にいます.これを一つに纏めて見やすくしたい.一手間加えます.
空の列を用意して,そこへ式をセットします(下記図参照).
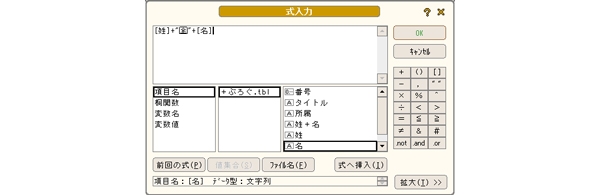
この式だけです.下記図のように姓と名が一つになった列の出来上がりです.
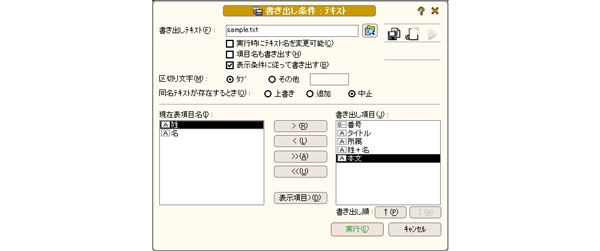
「桐」での最後の手順はテキスト書きだしです.列を指定します(下記図参照).
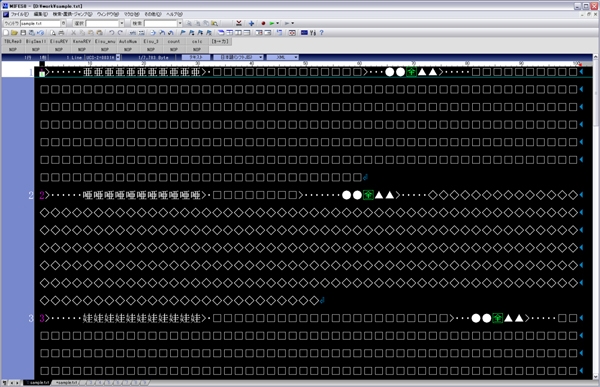
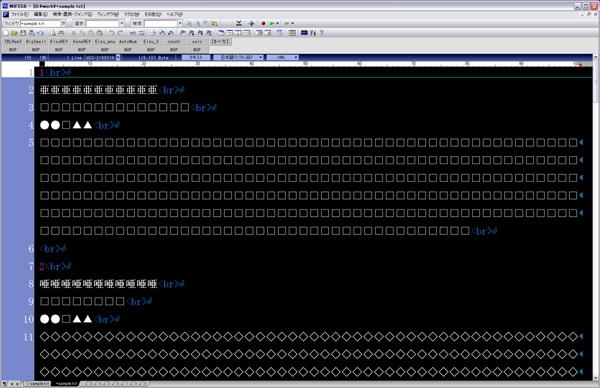
テキストエディターで開くと,下記の図のような「タブ区切り」のテキストとなります.
タブをすべて段落に変えた後,段落の手前に<br>を挿入するだけです(下記図参照).テキスト整形については割愛いたします.
最後は拡張子の「txt」を「html」に変えてブラウザで開くと下記のように表示されます.
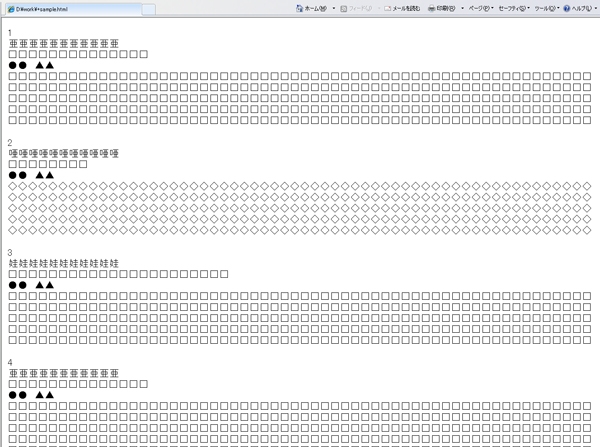
これを印刷すれば原稿の出来上がりです.
エクセルからのプリントの場合,列がプリント用紙に収まりきらない.セルに隠れた文字が印刷されないなど,いくつかの問題が発生する場合があります.
データベースを活用してHTML化することによって,校正者が見やすい原稿を作ることが可能となります.
生産部のHです。
組版の業務の一つにテキストの提供があります。それはプレーンなものから特定の項目にタグを付けたものまで様々なのですが、時折あるのが抽出です。
例えば➡の行のみテキストが欲しい(図1)。
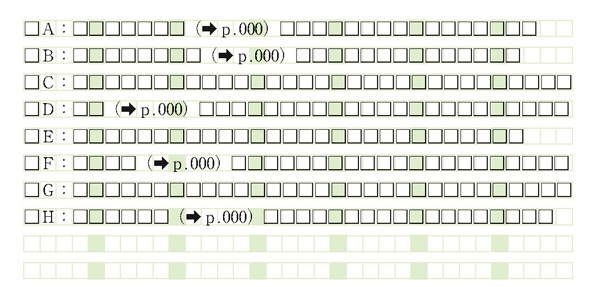
図1
この場合、コピーペーストが一般的かと思いますが、本一冊からでは大変な作業となります。そこでデータベースソフトの「桐」を活用していきます。
まずは図1の組版データをプレーンテキストにします(図2)。
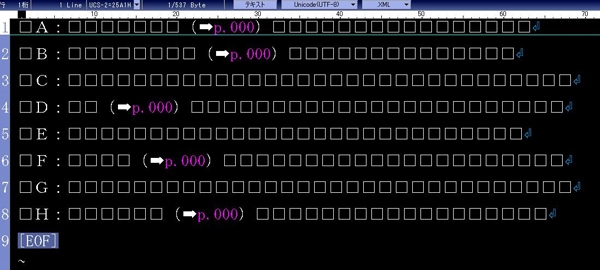
図2
このテキストを「桐」へインポート(図3)。詳細な手順は割愛したしますが、インポートするだけです。
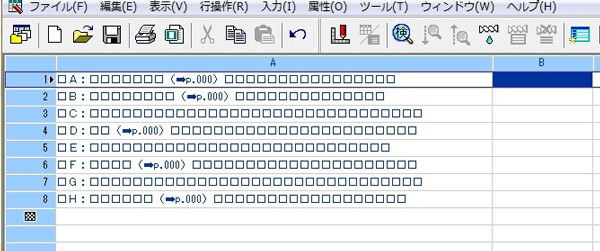
図3
ここで「桐」の機能である絞り込みを使います。
Aの列に対して➡のある行を絞ります(図4)。
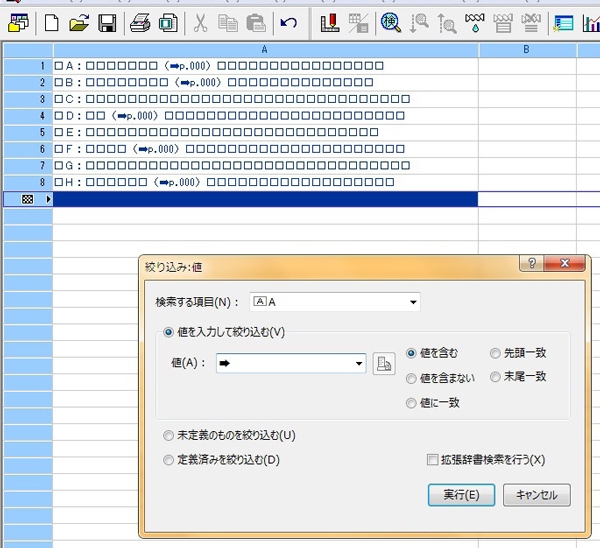
図4
この機能によって➡だけのデータが出来上がります(図5)。
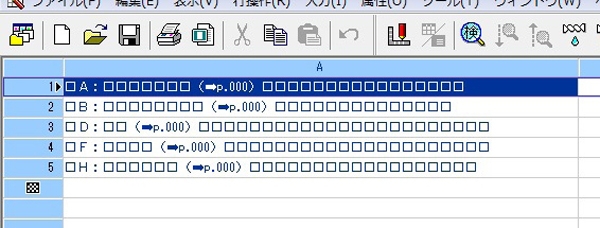
図5
あとは、テキストに書き出すのみです(図6)。
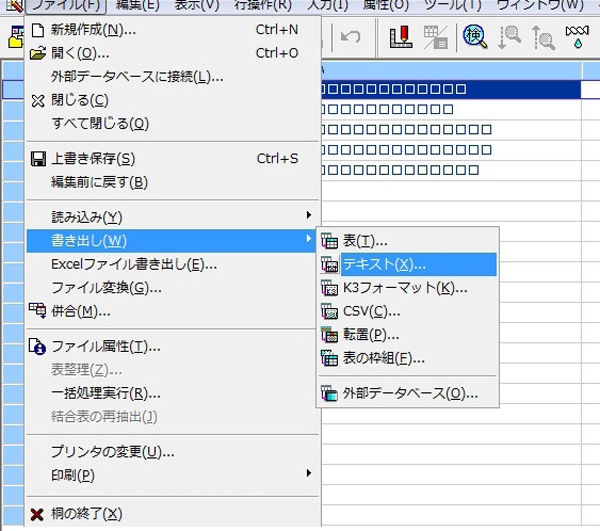
図6
出来上がりです(図7)。

図7
こういったソフトの機能を使うことにより、膨大な手作業を省略することができます。これも短納期で正確な作業を目指す一つの手段かと思っております。
IT・情報処理室のTです。
前回、前々回とバッチファイルの作成方法を中心に勉強しました。
3回目となる今回は、日常の業務に役立ちそうなコマンドをいくつか紹介していきたいと思います。
まずは第1回目でも勉強したCopyです。
以前は例としてフォルダ内全てのテキストを結合する方法を勉強しましたが、
以下のようにすると,特定のテキストのみを結合することも可能です。
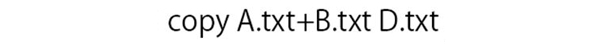
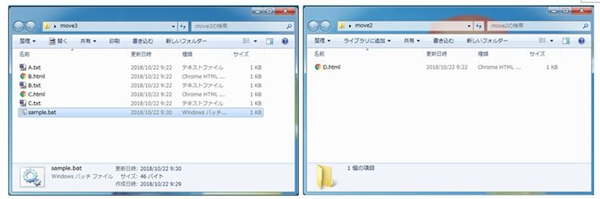
実際のデータを見てみると、フォルダ内にA、B、Cの3つのテキストがありますが、
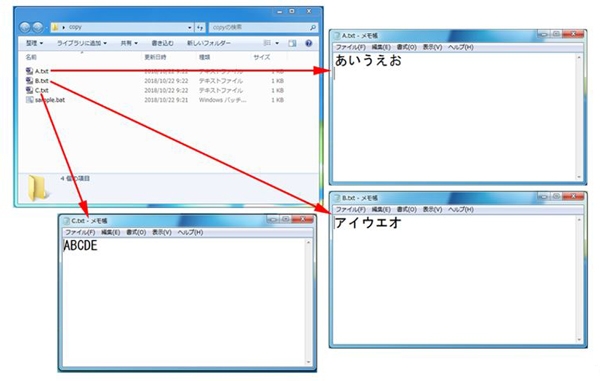
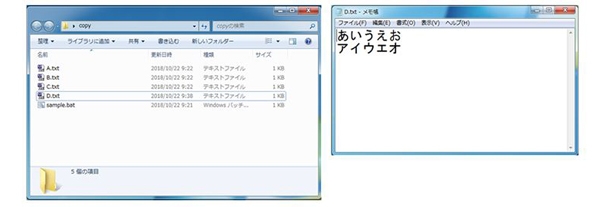
バッチファイルを実行すると、AとBのテキストのみが結合されたDテキストが作成されます。
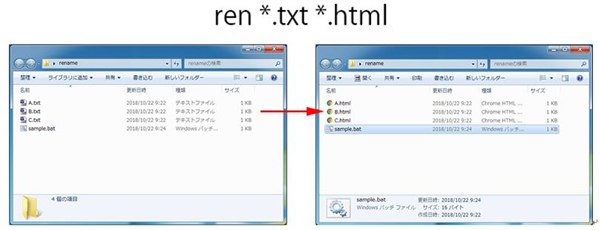
次に紹介するのはrenameです。
これは名前の通りリネームをするためのコマンドなのですが,
以下のようにすると,ファイルの拡張子のみを変えることができます。
最後に紹介するのはmoveです
これも名前の通りファイルを移動するコマンドなのですが,
以下のようにすると,特定の拡張子のファイルのみをまとめて移動することができます。
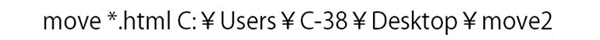
実際のファイルの動き方を見てみると、左側のフォルダ内にテキストファイルとHTMLファイルがありますが、
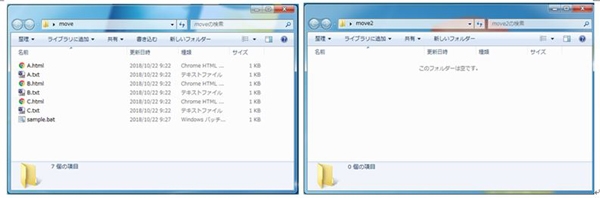
バッチファイルを実行すると、HTMLファイルのみが右側のフォルダに移動します。
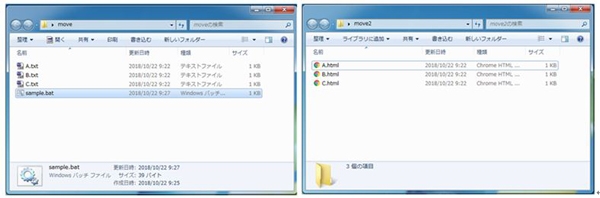
また移動するファイルが1つだけの時に限りますが、
以下のようにすると,移動と同時にファイル名を変更することができます。
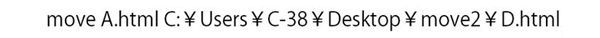
実際のファイルの動き方を見てみると、左側のフォルダ内にあるA.htmlが、
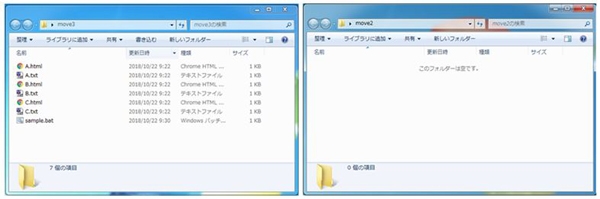
バッチファイルを実行すると、D.htmlにリネームされ右側のフォルダに移動します。
以上でバッチファイルの紹介は終わりとなりますが,皆さん業務に役立ちそうなものは見つかったでしょうか。
3回に渡ってバッチファイルの勉強をしてきましたが,紹介したコマンドは基本的なもののごく一部で,まだまだたくさんのコマンドがあります。その中には皆さんが日頃手間がかかるなと思っている作業の効率を上げるものがあるかもしれません。
今回のバッチファイルの勉強が皆さんの作業効率upを考えるきっかけとなることができれば幸いです。
江戸川工務Fです。
印刷刷り出しのチェックを日々行っているのですが、まだまだ色調に関しては不明なことが多く、何色のインキ量を増やしたり減らしたりの指示が難しいです。毎日できるだけ多くの印刷物に触れて目を肥やしていきたいと思っております。
今回は、その日々の刷り出しチェックの中で感じたことを書きたいと思います。
よくカバー、表紙や品質要求度が高い案件に関して営業からの指示で「原稿どおりに」や「原稿に忠実に」と言う言葉を見たり聞いたりします。これでは中々印刷物のイメージ付きにくいのでそれだけではなく、「原稿どおりに。ただしこの画像の○○な部分がポイントです」と補足することによりこちらも品質に関しての着眼点もはっきりしやすくなり、出来上がりの印象はかなり違ったものになると思われます。
以上の様にイメージ(色調)の指示は、言葉での伝達が重要なポイントになるわけですが、イメージを伝える言葉は校正記号のように規格化されたものではなく、人によってその表現方法はまちまちです。各人の好みや記憶色(被写体として記憶している色。例えば「みかん色」や「空色」など)も異なる為、それを把握して正確に現場に伝達することはとても難しいことです。そこで、たとえば「色味」に関して正しく伝えようとする場合、以下の3つのポイントを押さえて下さい。
- 色相:色そのものの事で「赤っぽい方向に」とか色の名前を使って表現します。
- 彩度:色の鮮やかさの事で、現状より「鮮やか」か「くすんでいる」かのどちらかで表現します。
- 明度:明るさの事で、今よりも「明るい」か「暗い」かのどちらかで表現します。
これらのポイントを抑えてお客様とやり取りをしていき、色調に関する指示を明確にしていくことによりお客様の要望している品質の印刷物に仕上がっていくと思います。
また、これらのポイントに関しては、印刷刷り出しを確認する工務も現場に指示する際に重要であると思います。このことを踏まえて今後も刷り出し確認や色調に関する調整指示を明確にし、より高品質な印刷物を作り上げていける様に自身の「色見」のスキルを上げていきたいです。
IT・情報処理室のMです。
最近、下版後の組版データより2次利用目的としてXMLやExcel等のデータへ書き出す機会が増えてきたので、組版段階からXMLを利用することにより、もう少し効率的に各種データを作成できるのではないかと思いまして、以前より興味がありましたInDesignを使用したXML組版について色々調べてみました。
まずは手始めに、InDesignのXMLに関連する機能について調べまして、特に優れていると思われる機能がありましたので、いくつか挙げてみたいと思います。
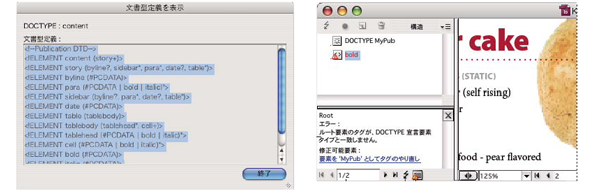
●DTDを使用してXMLを検証することが可能
取り込んだXMLが DTDで設定された規則からはずれていると、InDesign上で警告が出力されるので、文書構造の統一化を図ることができます。
※DTDについてはXML文書の構造定義について(1)で説明しています。
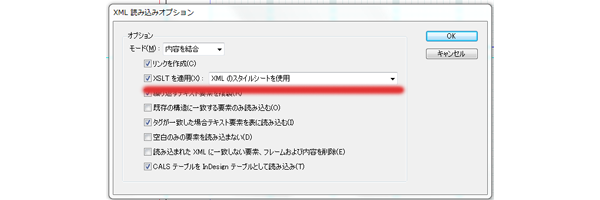
●XSLTで定義されたテンプレートに従ってさまざまな構造文書に変換が可能
XSLTを使用することによりXMLをさまざまな構造文書に変換して『読み込み』『書き出し』することができます。
※XSLT(XSL Transformations)は、W3Cにより標準化されたXMLの変換用言語
●段落スタイルまたは文字スタイルにXMLタグをマッピングすることが可能
InDesign上で定義した段落スタイルや文字スタイルを、XMLタグにマッピングすることが可能で、また、同じタグに複数のスタイルをマップすることもできます。
※逆にXMLタグにスタイルをマッピングすることも可能
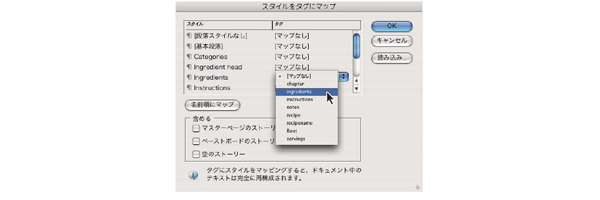
●タグマーカーおよびタグ付きフレームの表示と非表示の切り替えが可能
タグマーカーは、ページ上でタグ付きテキストの前後に表示されるブラケットで、タグマーカーを表示することにより、タグ付けされている場所を確認しながら編集作業ができるので視覚的に分かりやすい。

今回いくつか優れている点を挙げましたが、実際にInDesign上でXMLを扱うには、XMLの基礎技術・利用技術を持ち合わせていないと厳しい印象を受けましたが、組版や2次利用データ作成等を効率的に処理していく上で、XMLの技術は覚えておいて絶対損はしないと思いますので、これを機にInDesignを使用したXML組版に取り組んでみてはいかがでしょうか(私もですが ( ̄∇ ̄) )。
Adobe® product screenshot(s) reprinted with permission from Adobe® Systems Incorporated.
IT・情報処理室のMです。
前回はXML Schema記述例の2行目までしか説明できませんでしたが、今回は残りの行を見ていきたいと思います。
●前回のXML Schema記述例
<?xml version="1.0"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="root">
<xsd:complexType>
<xsd:sequence>
<xsd:element ref="data" minOccurs="0" maxOccurs="unbounded" />
</xsd:sequence>
<xsd:attribute name="age" type="xsd:nonNegativeInteger" use="required" />
</xsd:complexType>
</xsd:element>
<xsd:element name="data">
<xsd:complexType>
<xsd:sequence>
<xsd:element name=" firstName " type="xsd:string" />
<xsd:element name=" lastName " type="xsd:string" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>
それでは、残りの行を見ていきましょう。
3行目ではXMLの構造について表現します。今回作成するXML文書のルート要素名は「root」ですので、name属性の値は「root」となります。
4~9行目までは要素の型定義を表現しています。
6行目では『xsd:element ref="data"』と宣言していますが、name属性を使用せずにref属性を使用しています。
ref属性を記述した場合、要素の構造については別の場所で宣言します。そして、ref属性の値に記されている要素、つまり11行目の『xsd:element name="data"』を参照していることになります。

また、『minOccurs="0" maxOccurs="unbounded"』と記述されていますが、同じ要素が繰り返し出現する場合は、minOccurs属性およびmaxOccurs属性を使用します。minOccurs属性は、「要素を最低何回記述しなければならないか」を指定する属性で、maxOccurs属性は、「要素を何個まで書くことができるか」を指定します。今回のようにminOccurs属性の値に「0」、maxOccurs属性の値に「unbounded」を指定した場合は、「data要素を0個以上何個でも記述することができる」ことを表しています。
8行目では属性を定義していますが、属性を定義する際は『xsd:attribute』要素を使用して宣言します。属性の名前は、要素と同じようにname属性の値に指定します。ここでは「age」という名前の属性を宣言するので、name属性の値には「age」と記述します。
また、『type="xsd:nonNegativeInteger" use="required"』と記述されていますが、type属性は属性のデータ型(属性値としてどのような値が記述できるか)を記述し、use属性は属性の必須/任意や固定値指定などを記述します。今回のようにtype属性の値に「xsd:nonNegativeInteger」、use属性の値に「required」を指定した場合は、「0以上の整数を必ず記述しなければならない」ことを表しています。
11~18行目までは要素である「data」を定義しており、19行目は終了タグとなります。
今回もそうですがXML Schemaについて駆け足での説明になってしまいましたが、少しでもXMLに興味を持っていただけたら嬉しいです (*⌒▽⌒*)。
参考サイト:SEのためのXML Schema入門(1)~(3)- @IT
IT・情報処理室のMです。
前回は『DTD』と『XML Schema』の異なる点と記述例について書きましたが、今回は『XML Schema』の記述例についてもう少し具体的に説明いきたいと思います。
●前回のXML Schema記述例
<?xml version="1.0"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="root">
<xsd:complexType>
<xsd:sequence>
<xsd:element ref="data" minOccurs="0" maxOccurs="unbounded" />
</xsd:sequence>
<xsd:attribute name="age" type="xsd:nonNegativeInteger" use="required" />
</xsd:complexType>
</xsd:element>
<xsd:element name="data">
<xsd:complexType>
<xsd:sequence>
<xsd:element name=" firstName " type="xsd:string" />
<xsd:element name=" lastName " type="xsd:string" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>
では、1行目から確認していきましょう。
1行目はXML宣言です。XML SchemaはXMLの構造を表すための言語ですが、XML Schemaそれ自体もXML文書ですので、XMLの文法に沿って要素や属性を記述しなければなりません。
次に2行目はルート要素を示しておりXML Schemaのルート要素は“schema”になります。
ですが、要素名“schema”の頭に、“xsd:”という文字列が記述されていますが、これは『名前空間』と呼ばれる代物です。
ところで名前空間とは何かというと、XMLでは、要素や属性などを自由に作成することができますので、もしかしたらschemaという名前の要素が、どこかでまったく別の用途に使用されているかもしれません。
そこで、「ここでのschemaという要素は、XML Schemaで定義されたものである」ということを、明確に指示する必要があり、そのためXMLには名前空間と呼ばれる仕組みが用意されています。
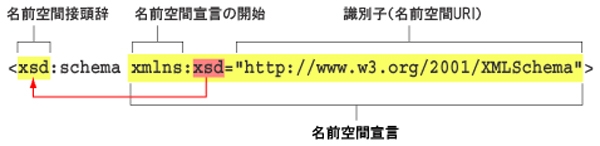
「xmlns:xsd="http://www.w3.org/2001/XMLSchema"」※1の部分ですが、「要素名の先頭にxsd:と付いたら、“http://www.w3.org/2001/XMLSchema”で定義された要素である」と宣言しています。これを『名前空間宣言』といいます。
また、“xsd”を使って“xsd:schema”と書くと、「XML Schemaのschema要素」という意味になり、この例の“xsd”のことを、『名前空間接頭辞』※2といいます。
やっと3行目からXML文書の構造定義について表記していくのですが、前回同様に今回も説明が長くなってしまいましたので、次回に詳しい説明をしたいと思います。
※1 “http://www.w3.org/2001/XMLSchema”はXML Schemaを表す識別子(名前空間URI)なのですが、特にURIに決まりはなく他と違えばなんでもよいのですが、“http://www.w3.org/2001/XMLSchema”をURIとして使用することが多いようです。
※2 名前空間接頭辞は単に各要素を結びつける役割を果たすだけの文字列ですので、“xsd”だけではなく任意の文字列を使用することができます。
参考サイト:SEのためのXML Schema入門(1):簡単なXML Schemaから始めよう - @IT
IT・情報処理室のMです。
前回はXML文書の構造を定義するためスキーマ言語の『DTD』について説明しましたが、今回は『XML Schema』について書いてみたいと思います。
ですがその前に、「毎回XMLについて偉そうに説明しているけど、本当に理解した上で説明してるの?」等の疑問の声が聞こえてきそうですが、私自身、ベンダーニュートラルな資格ではあるのですが、【XMLマスター:ベーシック】【XMLマスター:プロフェッショナル(アプリケーション開発)】という資格を数年前に取得しておりまして、その際に脳みそがオーバーヒートをするのではないかと思うくらい勉強し、XMLについての基礎知識は蓄えたつもりなので、たぶん大丈夫かと… (^_^;)
それでは気を取り直して、前回のDTDを参考にしてXML Schemaを実際に記述してみたいと思います。
●前回のDTD記述例
<!DOCTYPE root[
<!ELEMENT root (data*)>
<!ELEMENT data (firstName, lastName)>
<!ATTLIST data age CDATA #REQUIRED>
<!ELEMENT firstName (#PCDATA)>
<!ELEMENT lastName (#PCDATA)>
]>
●前回のDTDを参考にして作成したXML Schema記述例
<?xml version="1.0"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="root">
<xsd:complexType>
<xsd:sequence>
<xsd:element ref="data" minOccurs="0" maxOccurs="unbounded" />
</xsd:sequence>
<xsd:attribute name="age" type="xsd:nonNegativeInteger" use="required" />
</xsd:complexType>
</xsd:element>
<xsd:element name="data">
<xsd:complexType>
<xsd:sequence>
<xsd:element name=" firstName " type="xsd:string" />
<xsd:element name=" lastName " type="xsd:string" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>
どうですか。 上記の記述例でDTDとXML Schemaとでは文法が全然違うことが分かると思います。
そもそもなぜDTDとXML Schemaの記述方法が異なるのかというと、DTDはもともとSGML※1のスキーマ言語として開発された言語であり、現在でもHTML・XHTML等の文書構造定義として使用されております。
ですが最近では、スキーマ言語としてDTDを使用するケースは少なくなる傾向にあるそうで、その理由としては『XMLの文法とは異なる文法を採用している』『名前空間に対応していない』『データ型が定義できない』等の柔軟性に欠けることが考えられます。
その点、XML Schema はDTDの欠点を補う文書構造定義の方法として考案されており、『XML形式で記述できる』『データ型を定義できる』『名前空間を利用できる』等の拡張性に優れたスキーマ言語となっています。
「それじゃDTDを使わないでXML Schemaだけで文書構造定義をすればいいのでは?」と思ってしまいそうですが、上記の記述例を見てわかるように構造が複雑な上、扱えるデータ型の種類も豊富に存在するため、実際に文書構造定義を作成する際にはそれなりの知識が必要となりますし、また、同じ内容の定義をするにも何通りもの記述方法が可能なため、 取り扱いは煩雑なものとなります。
それではXML Schema記述例について説明していきたいのですが、前説が長くなってしまったので、次回に詳しい説明をしたいと思いますm(_ _)m。
※1 SGML(Standard Generalized Markup Language)は、主にマニュアル等の文書作成のためのマークアップ言語

