

「IVS」とは
那須工場 テキスト変換課のHです。
突然ですが、「IVS」というものをご存じでしょうか?
フォントに関する用語で、Ideographic Variation Sequence(異体字シーケンス)の略称です。
「IVS」とは何か・・?
この説明をする前に、「字形によって変わる文字」について触れてみたいと思います。
◉「字形によって変わる文字」とは
字形の規格「JIS90」「JIS2004」に基づいた漢字のことで、例えば「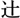 」という漢字で、一点しんにょうの「」は「JIS90」、二点しんにょうの「
」という漢字で、一点しんにょうの「」は「JIS90」、二点しんにょうの「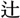 」は「JIS2004」といった具合です。
」は「JIS2004」といった具合です。
字形によって変わる文字の例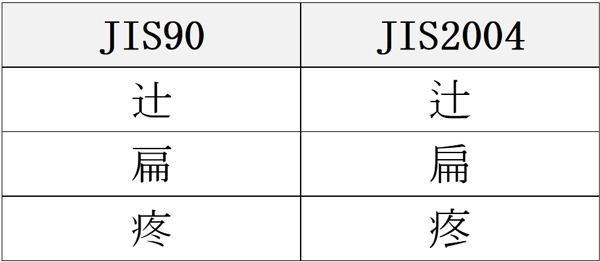
これらは一見すると「Shift-JISとUnicode間の異体字」と同じように見えますが、性質が全く異なるものになります。
◉「Shift-JISとUnicode間の異体字」との違い
まず、「Shift-JISとUnicode間の異体字」の例を挙げると、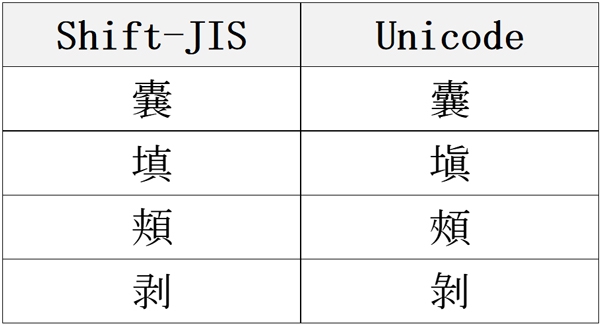
といった感じです。
先ほどの「字形によって変わる文字」同様、異体字を持つ漢字という点では同じように見えます。
では何がそんなに違うのかというと、異体字が別の文字コードを持つか持たないかです。
ここまで例に挙げた漢字に、それぞれ文字コードを記載してみると、
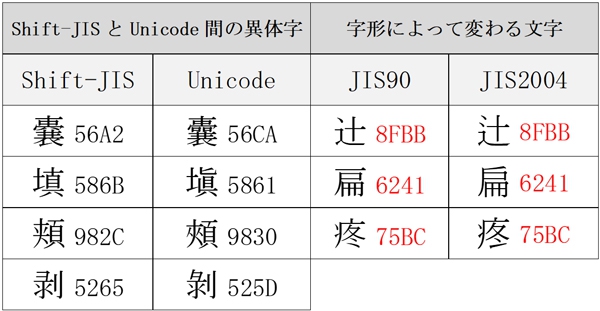
「Shift-JISとUnicode間の異体字」は、それぞれが別の文字コードを持っているのに対して、「字形によって変わる文字」は、異体字でも同じ文字コードを持っているという事が分かるかと思います。
◉文字コードが同じだと何が問題なのか
文字コードが違えばそれぞれ別の文字という認識となり、一つのデータ内でも文字を使い分ける事が可能となります。
対して文字コードが同じという事は、文字コードが同じ=同じ文字という認識となってしまうため、一つのデータ内で文字を使い分ける事が困難になってしまいます。
フォントによっては字形を変えられるものもあるので、文字単位でフォントが変えられるWordのような形式であれば、一つのデータ内で複数の字形を使い分けることが可能となりますが、テキストデータのような形式だと文字単位でフォントを変えることができないため、通常は一つのテキストデータ内で一つの字形しか使用できません。
◉「IVS」という技術
そこで役立つのが、今回のテーマでもある「IVS」という技術です。
「IVS」という技術について簡潔に説明をすると、本来なら個別の文字コードを持っていない「字形によって変わる文字」に対して、文字コードを割り当てていくことで、文字コードが違う=別の文字という認識に変わり、文字の使い分けが可能になるという技術です。
以下は「IVS」を用いたATOKでの変換画面です。
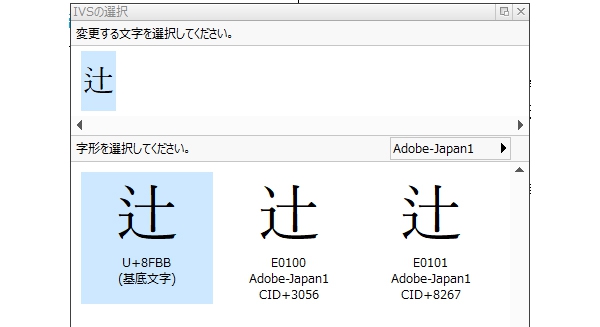
本来、文字コードが同じはずの「」と「」に対して、それぞれ「E0100」「E0101」という文字コードが割り当てられています。
テキストデータ上で文字コードを確認すると、「8FBB[0]」「8FBB[1]」となっていました。
「」そのものの文字コード「8FBB」に[0]、[1]と枝番を振っていく、という仕組みのようです。
◉「IVS」の注意点【フォント編】
「IVS」の文字を使用する際は、対応フォントでなければ機能しないという点に注意しなくてはいけません。
非対応フォントの環境では「IVS」の文字が入力できませんし、元々「IVS」の文字が入力してあったとしても、見た目が変わってしまいます。
例)「JIS90」字形での「」の場合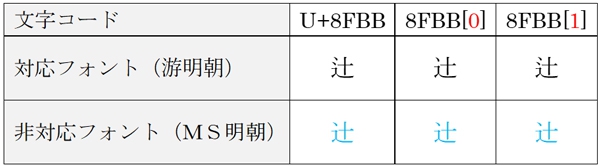
非対応フォントだと見た目はすべて「JIS90」の「」になってしまいますが、文字コード自体は活きているので、対応フォントに変えれば見た目もまた「IVS」の文字に戻ります。
対応フォントの例を挙げると、「メイリオ」「ヒラギノ ProN」「モリサワフォント Pr6」「游書体ライブラリー Pr6N」「IPAmj明朝」などです。
Windows標準フォントである「MS明朝」や「MSゴシック」などは対応していないようです。
上記の対応フォントは入力方式が「ATOK」の場合らしいのですが、入力方式が「IME」で尚且つWindows 8以降の環境であれば、「MS明朝」や「MSゴシック」でも「IVS」が使用可能になる、との記載を見つけました。
ですが、当方で試した限りは残念ながら実証に至りませんでしたので、「IME」での対応フォントについては割愛させていただきます。
◉「IVS」の注意点【文字コード編】
対応フォントにも注意が必要ですが、枝番で振られた文字コードにも注意が必要です。
文字コードに注目して、ATOKでの変換画面をもう一度見てみると、
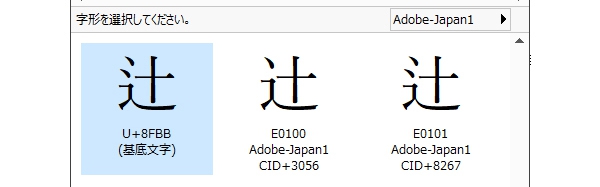
一点しんにょうの「」は文字コード「E0100」なのに対して、
二点しんにょうの「」は文字コード「U+8FBB」「E0101」と、二つの文字コードを持っていることが分かります。
なぜこのようなことが起きてしまうのかというと、「U+8FBB」というのは「」そのものの文字コードであって、設定している字形によっては「U+8FBB」=「」でもあるし、「U+8FBB」=「」でもあるためです。
元の文字コード「U+8FBB」が一点しんにょうの「」なのか、二点しんにょうの「」なのかは、それぞれ設定している環境によって違うため、「IVS」では基底となる「U+8FBB」がどちらなのかを断定できないのです。
それ故に、便宜上全ての字形に対して文字コードを振り分けることになっています。
そうなると、漢字の見た目は同じ「」でも、「U+8FBB」と「E0101」という二つの文字コードが存在することになってしまい、文字コードが違う=別の文字という認識になってしまうのです。
個別の文字コードが無かった字形に対して、文字コードを振り分けることで字形の使い分けが可能になる反面、全ての字形に文字コードを振り分けている影響で、元の文字コードと「IVS」で振り分けた文字コードの二つの文字コードを持つ漢字ができてしまう・・。
便利な機能ですが、若干ややこしい性質も持っていますね・・。
◉【フォント編】&【文字コード編】のまとめ
ここまでの注意点を踏まえて、テキスト作業・組版作業について考えてみましょう。
字形が「JIS90」の環境で、「」を使用する場合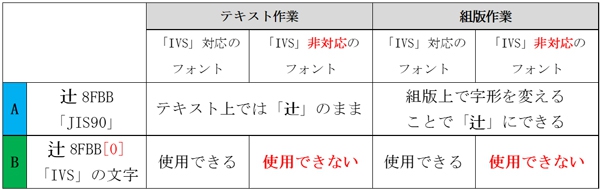
「IVS」の文字(B)を使用する
テキスト作業においては、「IVS」対応のフォントで作業すれば何も問題ないかと思います。
非対応のフォントで作業する場合は、前述の通り「IVS」の文字(B)を入力出来ません。ただし、元々「IVS」の文字(B)が使用されている場合は、見た目は変わってしまうけど文字コード自体は失われないので、「IVS」の文字コードを用いて文字変換などに活かすことが可能になります。(次項参照)
組版作業においては、組む場所によってフォントが変わってしまうと思うので、「IVS」に対応するフォントで組む部分に関しては問題ないのですが、「IVS」に非対応のフォントで組む部分に関しては「IVS」が効かない(=文字コードはそのままだけど、見た目が元の字形に戻ってしまう)ため、該当箇所のフォントが「IVS」に対応しているのかどうかを、毎回確認しなくてはいけなくなります。
複数のフォントが混在する組版作業において、「IVS」の文字(B)を使うたびに対応フォントの確認するのは、作業効率を下げてしまうし、非対応フォントに気づかず見た目が変わってしまった・・なんてミスを引き起こしかねませんので、組版作業上においては今まで通りの方法(元の文字コードの文字(A)を、組版上で字形を変える)が一番良いでしょう。
◉現状で考える「IVS」の活用方法
組版作業においては微妙な感じがしてしまう「IVS」ですが、組版作業に行くまでの工程、つまりテキスト作業においては、活用次第で十分役立つ技術かと思います。
例えば、テキスト作業までは対応フォントのもとで「IVS」の文字(B)を使用し、組版作業前の文字を整える作業(PERL、ruby、最終置換など)において、元の文字コードの文字(A)に戻しつつ、字形を変えるタグを挿入するという処理が可能となります。
字形が「JIS90」の環境で、「IVS」を用いて「」→「」にする流れ
「IVS」の文字はそれぞれ文字コードを持っているので、見た目が同じでも混在することなくタグ挿入などの処理が可能となります。
タグ挿入をしてから文字を流すことで、組版作業上でもちゃんと字形が変わっているので、現段階ではこれが最善の活用方法かなと思われます。
◉さいごに
今回から那須工場は、若いメンツで一人一回ずつ書いていこう!となりましたので、2019年から書き始めた自分の勉強部屋も、ひとまず今回で最後となります。
最初にこのお話しをいただいた時は不安でいっぱいでしたが、書いていく内に要領が分かってきて、読んでいただいた方々からも感想やツッコミをいただいたりしてとても楽しかったです。
また、自らの知識や技術を再確認する良き機会となり、執筆にあたって調べたり掘り下げたりすることで新たな発見をすることも多々ありましたので、自分にとっても大変勉強になりました。
拙い文章だったと思いますが、読んでいただいた方々、アドバイスや感想をくれた方々、そして勉強部屋を書くきっかけをくれた方々に本当に感謝しています。ありがとうございました。
次回、那須工場からはパソコン大好きなTくんが初登場します!
どんなオモシロ話やオモシロ知識が飛び出すのか・・ぜひご期待&温か~い目で見てあげてくださいね。