

PDFからのしおり抽出と再作成①
DTP1部のTです。
今回のブログではPDFからしおりのテキストを抽出、そのテキストを使用して別のPDFにしおりを作成する方法をご紹介していきたいとおもいます。
そもそも、そんな作業することがあるのかと疑問におもう方もいるかと思いますので、まずはどういった時に使用するのかといった所から。
昨今では以前よりも2次利用を目的としてPDFを作成する書籍が増えてきていますが、その中でも年度版で毎年再版を行うものは修正箇所が少なく、目次に修正がない場合などがあります。
そういった時にこれからご紹介する方法を使用することで手間のかかるしおり作成の作業時間を大幅に短縮することができます。
それではまず抽出を行うPDFをAcrobatで開き、デバッカーのコンソールに下記のスクリプトを貼り付けます。
function DumpBookmark(bkm, nLevel)
{
var s = "";
for (var i = 0; i < nLevel; i++) s += "\t";
bkm.execute();
console.println(s + bkm.name + "\t" + this.pageNum);
if (bkm.children != null)
for (var i =0; i < bkm.children.length; i++)
DumpBookmark(bkm.children[i], nLevel + 1);
}
console.clear(); console.show();
console.println("Dumping all bookmarks in the document.");
DumpBookmark(this.bookmarkRoot, 0);
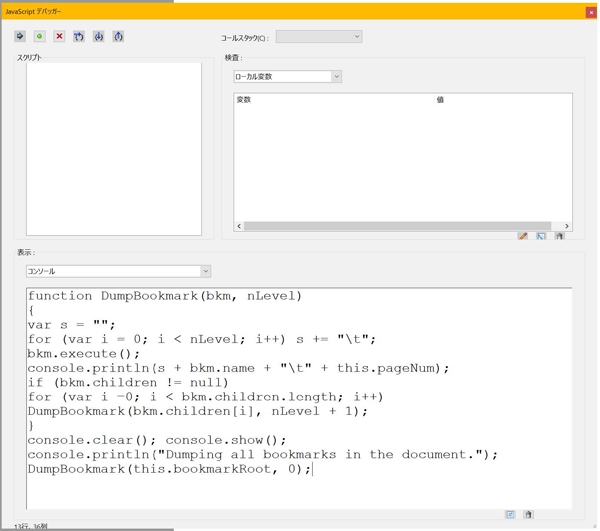
貼り付けたらテキストを全選択し、Enterを押します。
すると抽出が始まり、スクリプトを貼り付けたところに項目とページ番号が抽出されます。
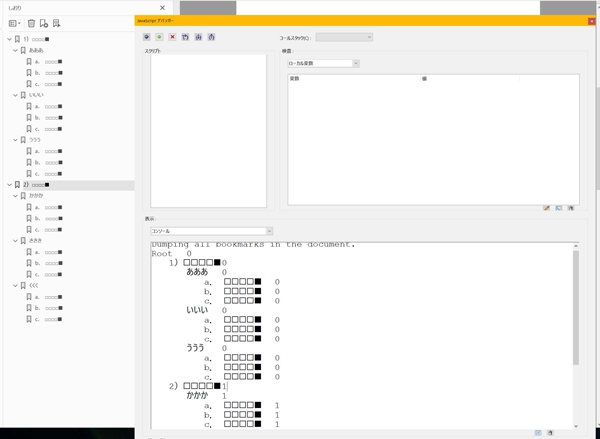
抽出テキストをテキストエディタに貼り付け、先頭にある
Dumping all bookmarks in the document.
Root 0
最終行の
undefined
は不要なので削除します。
これで抽出作業は完了です。
ここからこのテキストをもう一度しおりとして読み込ませるために、タグをつけていきます。
基本的な形は以下のようになります。
bookmarkRoot.createChild(" ●●● ","this.pageNum = 0",1);
最後にある数字(上記の見本では1になっている箇所)は、しおりを流し込む時の順番になります。
これを指定しておかないと流し込んだときに順番がおかしくなってしまうので注意してください。
タグをつけ終えたら新たにしおりを読み込ませるPDFを開きます。
そして抽出するときと同様にデバッカーのコンソールにタグをつけたテキストを貼り付け、全選択しEnter を押します。
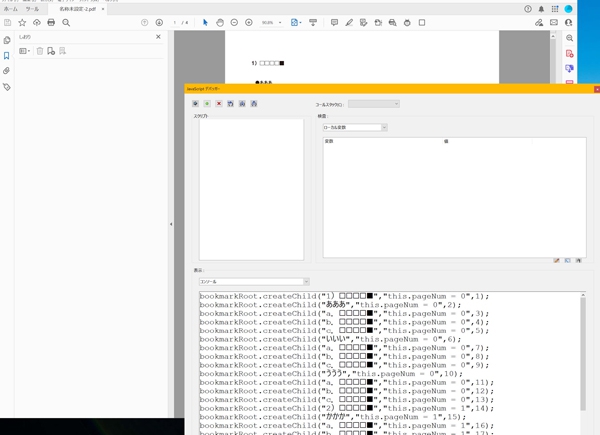
そうするとテキストが読み込まれ、新たにしおりが作成されます。
成功例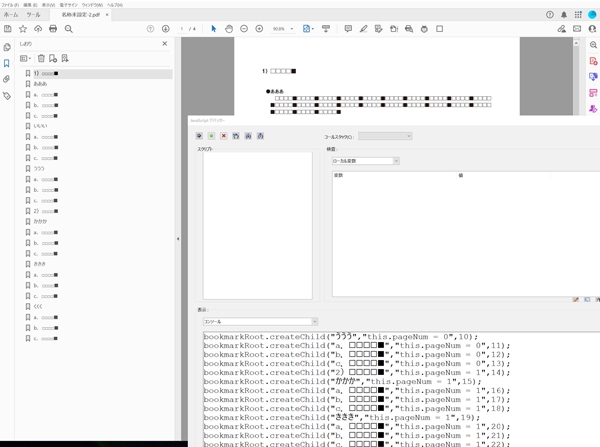
失敗例(順番の数字が全て1の場合)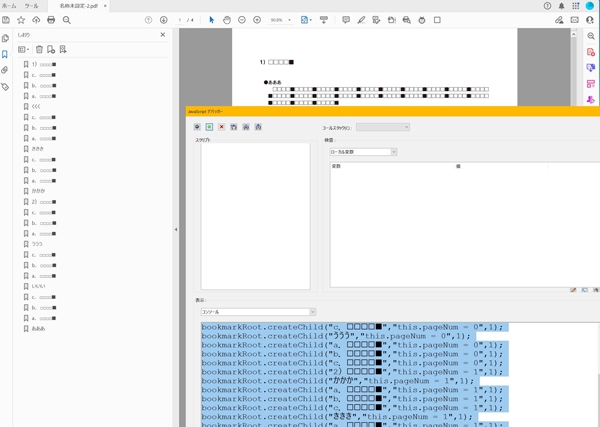
これで一先ずしおりは作成されました。
ただこれだけだと元々あった階層がなくなってしまったり、前付けのノンブルに時計数字を使用しているとしおりをクリックした
ときに正しいページに飛ばないなどの問題が発生してしまいます。
そういった問題を解決するためにデータベースソフト等を利用してここから手を加えていくのですが、
話しが長くなってしまうのでそれはまた次回にお話ししたいとおもいます。